
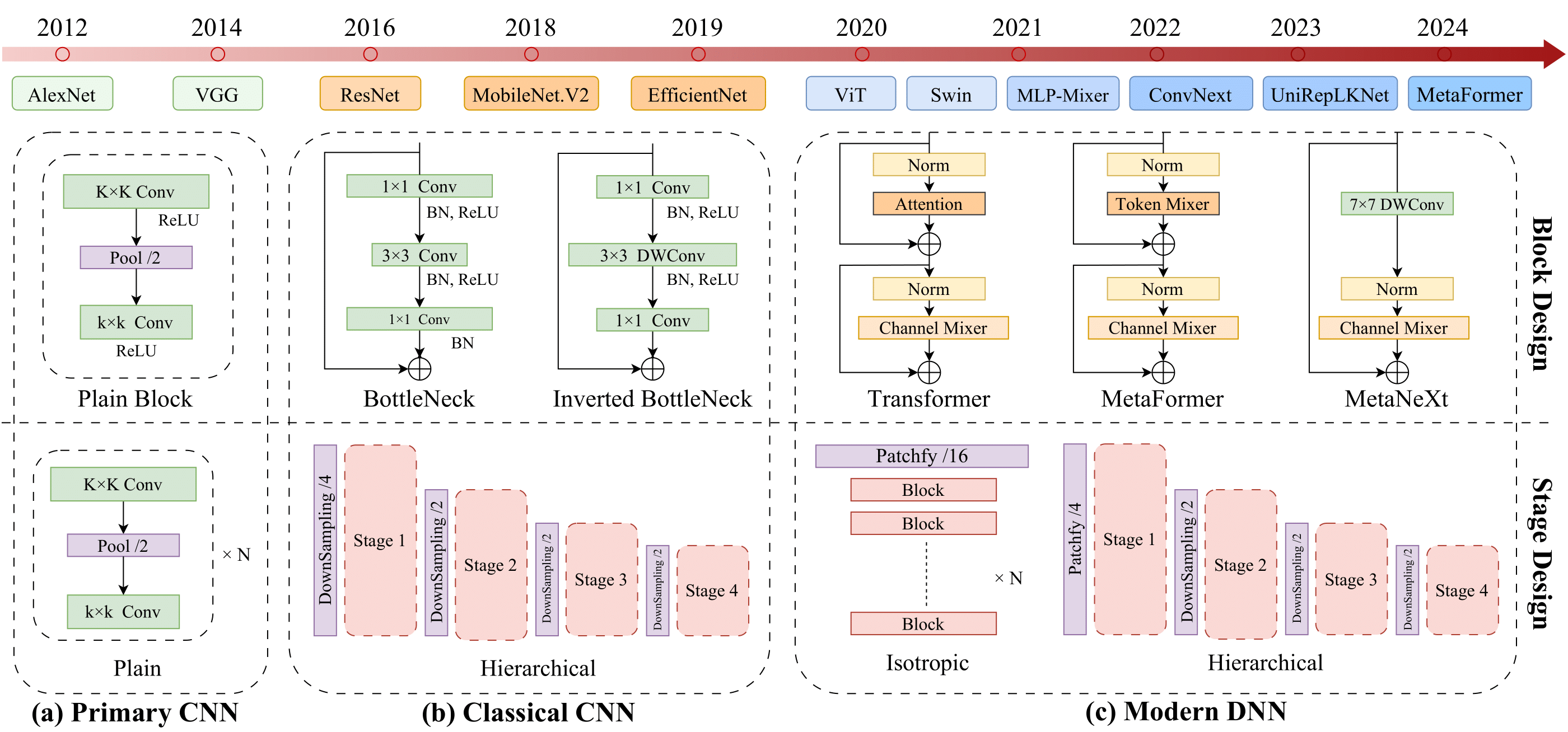
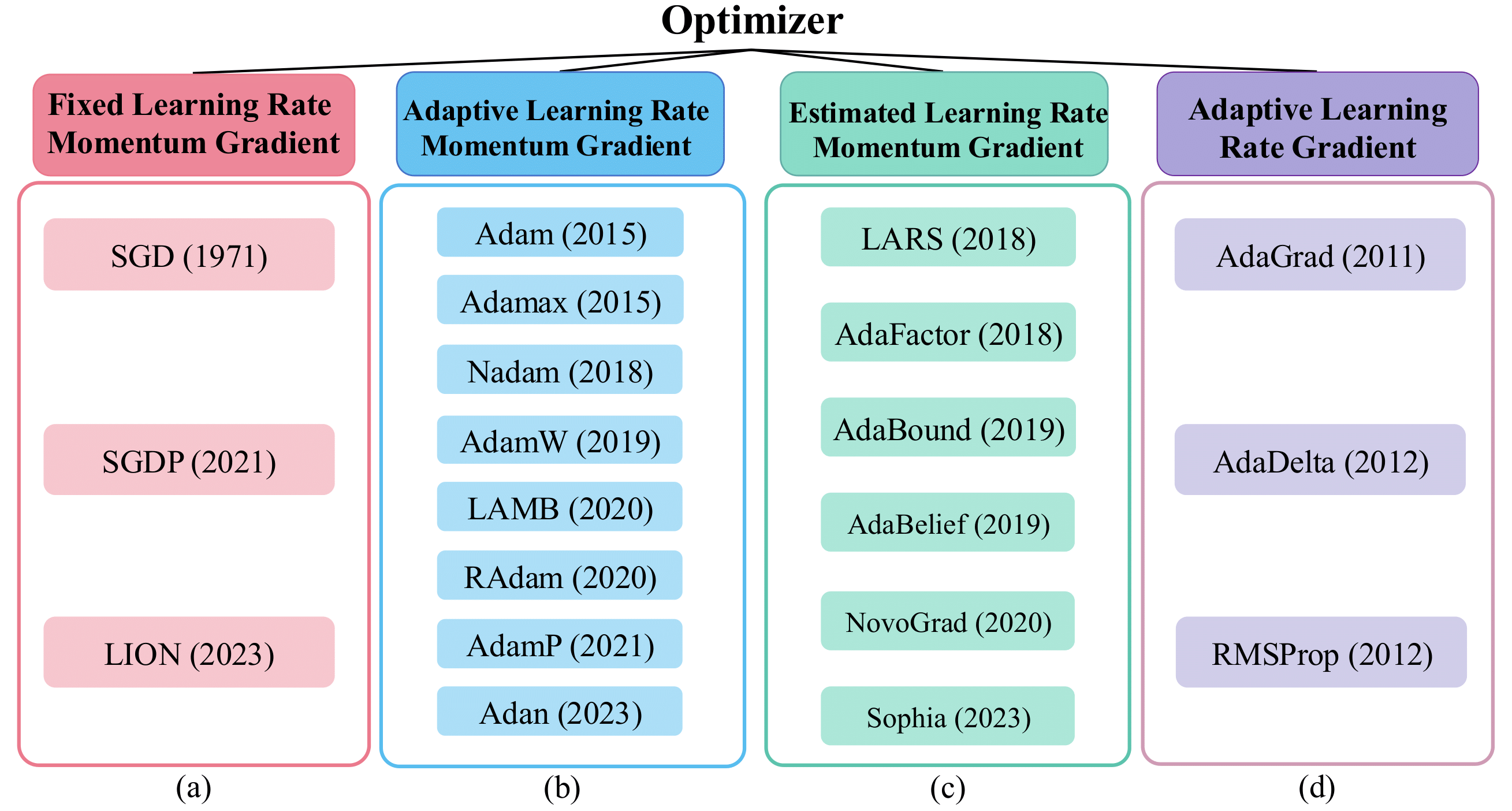

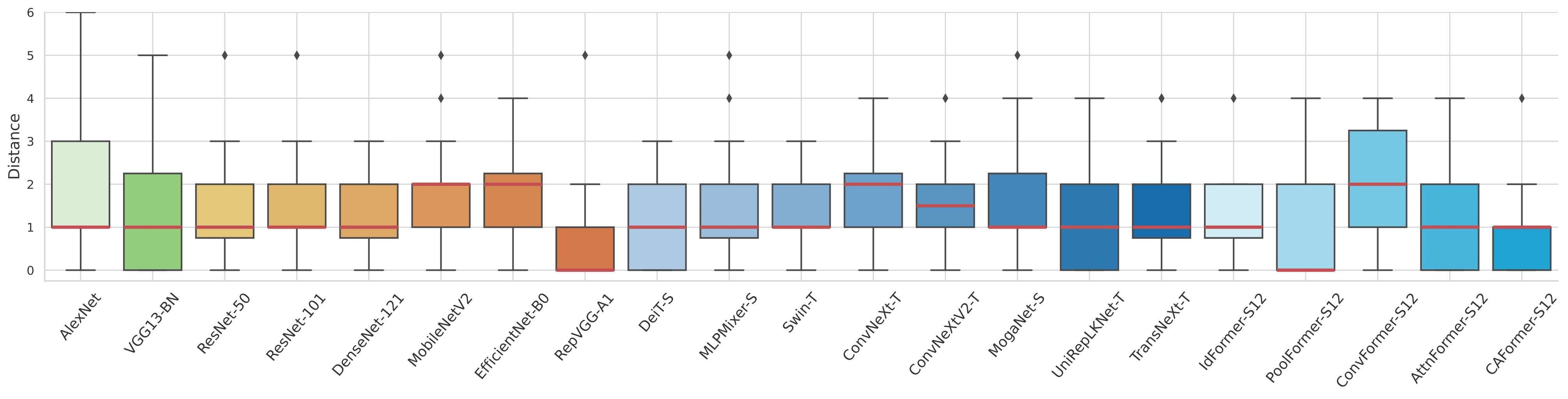
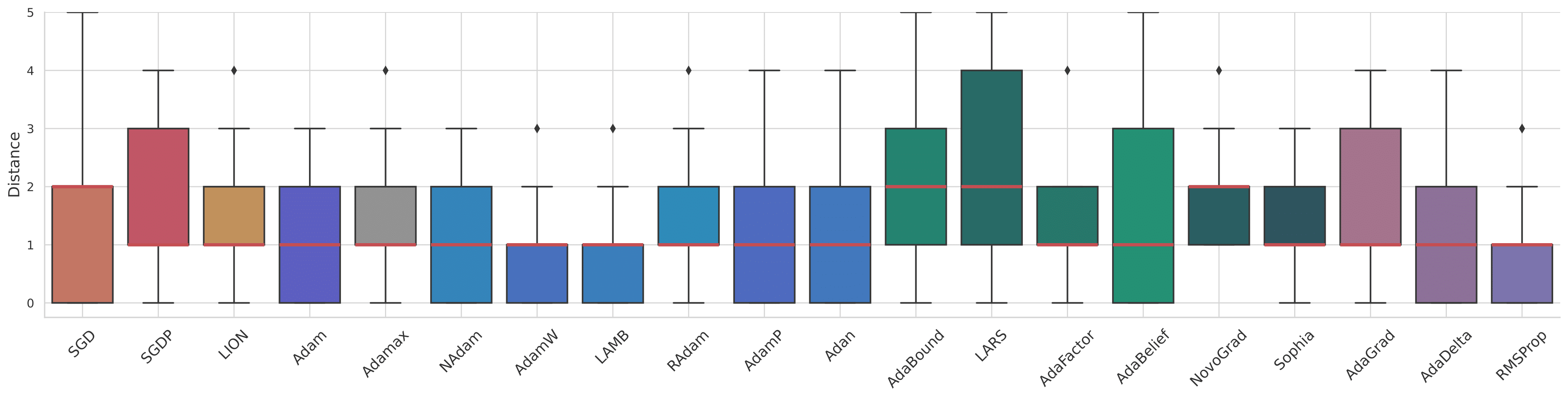
Top-1 accuracy (\%) of representative vision backbones with 20 popular optimizers on CIFAR-100. The torch-style training settings are used for AlexNet, VGG-13, R-50 (ResNet-50), DN-121 (DenseNet-121), MobV2 (MobileNet.V2), and RVGG-A1 (RepVGG-A1), while other backbones adopt modern recipes, including Eff-B0 (EfficientNet-B0), ViT variants, ConvNeXt variants (CNX-T and CNXV2-T), Moga-S (MogaNet-S), URLK-T (UniRepLKNet-T), and TNX-T (TransNeXt-T). We list MetaFormer S12 variants apart from other modern DNNs as IF-12, PFV2-12, CF-12, AF-12, and CAF-12.
The blue and gray features denote the top-4 and trivial results, while others are inliers.
Two bottom lines report mean, std, and range on statistics that removed the worst result for all models.
You can swipe left and right to see the full table.
| Backbone | AlexNet | VGG-13 | R-50 | DN-121 | MobV2 | Eff-B0 | RVGG-A1 | DeiT-S | MLP-S | Swin-T | CNX-T | CNXV2-T | Moga-S | URLK-T | TNX-T | IF-12 | PFV2-12 | CF-12 | AF-12 | CAF-12 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SGD-M | 66.76 | 77.08 | 78.76 | 78.01 | 77.16 | 79.41 | 72.64 | 75.85 | 63.20 | 78.95 | 60.09 | 82.25 | 75.93 | 82.75 | 86.21 | 77.40 | 77.70 | 83.46 | 83.02 | 81.21 |
| SGDP | 66.54 | 77.56 | 79.25 | 78.93 | 77.32 | 79.55 | 75.26 | 63.53 | 69.24 | 80.56 | 61.25 | 82.43 | 80.86 | 82.18 | 86.12 | 77.55 | 77.53 | 83.54 | 82.88 | 81.56 |
| LION | 62.11 | 73.87 | 75.28 | 75.42 | 74.62 | 76.97 | 73.55 | 74.57 | 74.19 | 81.84 | 82.29 | 82.53 | 85.03 | 83.43 | 86.96 | 78.65 | 79.66 | 84.62 | 82.41 | 79.59 |
| Adam | 65.29 | 73.41 | 74.55 | 76.78 | 74.56 | 76.48 | 75.06 | 71.04 | 72.84 | 80.71 | 82.03 | 82.66 | 84.92 | 84.73 | 86.23 | 78.39 | 79.18 | 84.81 | 81.54 | 82.18 |
| Adamax | 67.30 | 73.80 | 75.21 | 73.52 | 74.60 | 78.37 | 74.33 | 73.31 | 73.07 | 81.28 | 80.25 | 81.90 | 84.51 | 83.81 | 86.34 | 78.02 | 79.55 | 84.31 | 81.83 | 82.50 |
| NAdam | 60.49 | 73.96 | 74.82 | 76.10 | 75.08 | 77.06 | 74.86 | 72.75 | 73.77 | 81.80 | 82.26 | 82.72 | 85.23 | 82.07 | 86.44 | 78.37 | 80.32 | 84.81 | 81.82 | 82.83 |
| AdamW | 62.71 | 73.90 | 75.56 | 78.14 | 76.88 | 78.77 | 75.35 | 72.15 | 73.59 | 81.30 | 83.52 | 83.59 | 86.19 | 86.30 | 87.51 | 79.39 | 80.55 | 85.46 | 82.24 | 83.60 |
| LAMB | 66.90 | 75.55 | 77.19 | 78.81 | 77.59 | 78.77 | 77.04 | 75.39 | 74.98 | 83.47 | 84.13 | 84.93 | 86.04 | 84.99 | 87.37 | 80.21 | 80.01 | 85.40 | 83.16 | 83.74 |
| RAdam | 61.69 | 74.64 | 75.19 | 76.40 | 75.94 | 77.08 | 74.83 | 72.41 | 72.11 | 79.84 | 82.18 | 82.69 | 84.95 | 84.26 | 86.49 | 78.46 | 79.71 | 84.93 | 81.44 | 82.35 |
| AdamP | 60.27 | 75.56 | 78.17 | 78.89 | 77.79 | 78.65 | 77.67 | 71.55 | 73.66 | 80.91 | 84.47 | 84.40 | 86.45 | 86.19 | 87.16 | 79.20 | 81.70 | 85.15 | 82.12 | 83.40 |
| Adan | 63.98 | 74.90 | 77.08 | 79.33 | 77.73 | 78.43 | 76.99 | 76.33 | 74.94 | 83.35 | 84.65 | 84.77 | 86.46 | 86.75 | 87.47 | 80.59 | 83.23 | 85.58 | 83.51 | 84.89 |
| AdaBound | 66.59 | 77.00 | 78.11 | 75.26 | 78.76 | 79.88 | 74.14 | 68.59 | 70.31 | 80.67 | 71.96 | 83.90 | 78.48 | 83.03 | 86.07 | 77.99 | 77.81 | 82.73 | 83.08 | 82.38 |
| LARS | 64.35 | 75.71 | 78.25 | 77.25 | 76.23 | 72.43 | 75.50 | 71.36 | 72.64 | 81.29 | 61.40 | 82.22 | 33.26 | 41.03 | 85.16 | 77.66 | 78.78 | 82.98 | 81.00 | 82.05 |
| AdaFactor | 63.91 | 74.49 | 75.41 | 77.03 | 75.38 | 77.83 | 75.03 | 74.02 | 71.16 | 80.36 | 82.82 | 83.06 | 85.17 | 85.99 | 86.57 | 78.78 | 78.81 | 84.90 | 81.94 | 82.36 |
| AdaBelief | 62.98 | 75.09 | 80.53 | 79.26 | 75.78 | 78.48 | 76.90 | 70.66 | 73.30 | 80.98 | 83.31 | 84.47 | 84.80 | 84.54 | 86.64 | 78.55 | 81.01 | 85.03 | 83.21 | 83.56 |
| NovoGrad | 64.24 | 76.09 | 79.36 | 77.25 | 71.26 | 74.23 | 75.16 | 73.13 | 67.03 | 81.82 | 79.99 | 82.01 | 82.96 | 80.77 | 85.85 | 77.16 | 78.92 | 83.51 | 81.28 | 82.98 |
| Sophia | 64.30 | 74.18 | 75.19 | 77.91 | 76.60 | 78.95 | 75.85 | 71.47 | 72.74 | 80.61 | 83.76 | 83.94 | 85.39 | 84.20 | 86.60 | 77.67 | 78.90 | 84.58 | 81.67 | 82.96 |
| AdaGrad | 45.79 | 71.29 | 73.30 | 51.70 | 33.87 | 77.93 | 46.06 | 67.24 | 67.50 | 75.83 | 75.63 | 50.34 | 83.03 | 82.57 | 66.83 | 44.34 | 44.40 | 79.67 | 78.71 | 38.09 |
| AdaDelta | 66.87 | 74.14 | 75.07 | 76.82 | 75.32 | 77.88 | 74.58 | 65.44 | 71.32 | 80.25 | 74.25 | 82.74 | 81.06 | 84.17 | 85.31 | 75.91 | 76.40 | 84.05 | 82.62 | 82.08 |
| RMSProp | 59.33 | 73.30 | 74.25 | 75.45 | 73.94 | 76.83 | 74.92 | 70.71 | 71.63 | 77.52 | 82.29 | 82.11 | 85.17 | 61.14 | 86.21 | 77.40 | 77.14 | 84.01 | 79.72 | 81.83 |
| Mean | 63.67 | 74.68 | 76.31 | 76.94 | 75.65 | 77.77 | 75.19 | 70.82 | 72.10 | 80.63 | 78.13 | 82.92 | 83.51 | 82.40 | 86.34 | 78.03 | 78.94 | 84.28 | 81.99 | 82.32 |
| Std/Range | 1.1/8 | 1.0/4 | 1.6/6 | 1.4/6 | 1.6/8 | 1.2/6 | 0.9/4 | 2.9/13 | 1.7/8 | 1.1/6 | 8.0/25 | 0.8/3 | 2.8/11 | 5.5/26 | 0.6/2 | 0.8/5 | 1.2/7 | 0.8/3 | 0.9/4 | 0.9/5 |


